
Amazon Aurora DSQL, introduced in December 2024 as public preview, it is a serverless, distributed SQL database designed to provide virtually unlimited scalability, high availability, and zero infrastructure management. It is optimized for transactional workloads that benefit from ACID transactions and a relational data model.
Key Features of Amazon Aurora DSQL:
- Serverless Architecture: Aurora DSQL automatically scales compute, I/O, and storage to adapt to varying workload demands, eliminating the need for manual database sharding or instance upgrades.
- Active-Active Distributed Architecture: It ensures strong data consistency with 99.99% availability in single-Region configurations and 99.999% in multi-Region setups, making it ideal for building highly available applications.
- PostgreSQL Compatibility: Developers can leverage familiar PostgreSQL drivers, tools, and frameworks, facilitating rapid application development and deployment.
- Optimistic Concurrency Control (OCC): Aurora DSQL employs OCC to handle transactions, reducing the need for locking mechanisms and enhancing performance in distributed environments.
Benefits of Using Aurora DSQL:
- High Availability: Its innovative active-active architecture eliminates downtime due to failover or switchover, ensuring continuous application availability.
- Scalability: Aurora DSQL can scale to meet any workload demand without database sharding or instance upgrades, making it suitable for applications of all sizes.
- Zero Infrastructure Management: The serverless design eliminates the operational burden of patching, upgrades, and maintenance downtime, allowing developers to focus on application development.
Getting Started with Aurora DSQL:
- Cluster Creation: Quickly create new clusters through the AWS Management Console, AWS CLI, or AWS SDKs. In the below i will give you example of installation using AWS Management Console and connection with DBeaver.
- Application Development: Utilize PostgreSQL-compatible drivers and tools to build and deploy applications seamlessly.
- Data Loading: Use the Aurora DSQL loader, an open-source Python script, to load data into Aurora DSQL for testing or data transfer purposes.
Use Cases for Aurora DSQL:
- Microservices and Serverless Architectures: Its serverless nature and compatibility with PostgreSQL make it ideal for modern application architectures.
- Globally Distributed Applications: With multi-Region configurations offering 99.999% availability, it’s suitable for applications requiring global reach and high resilience.
- Transactional Workloads: Optimized for transactional workloads that benefit from ACID transactions and a relational data model.
How to install Aurora DSQL via Console?
Go to the AWS Management Console and search Aurora DSQL in the search bar.
Then Click Create Cluster in the service specific screen, choose other Region (Multi-Region, if you want to operate more than one Region, everything will be synchronized between regions, and you can read/write from each region)

How to connect Aurora DSQL?
I am using DBeaver as my client tool.
First we have to get connection details from AWS Console, all of the information can be retrieval via CLI and SDKs as well.
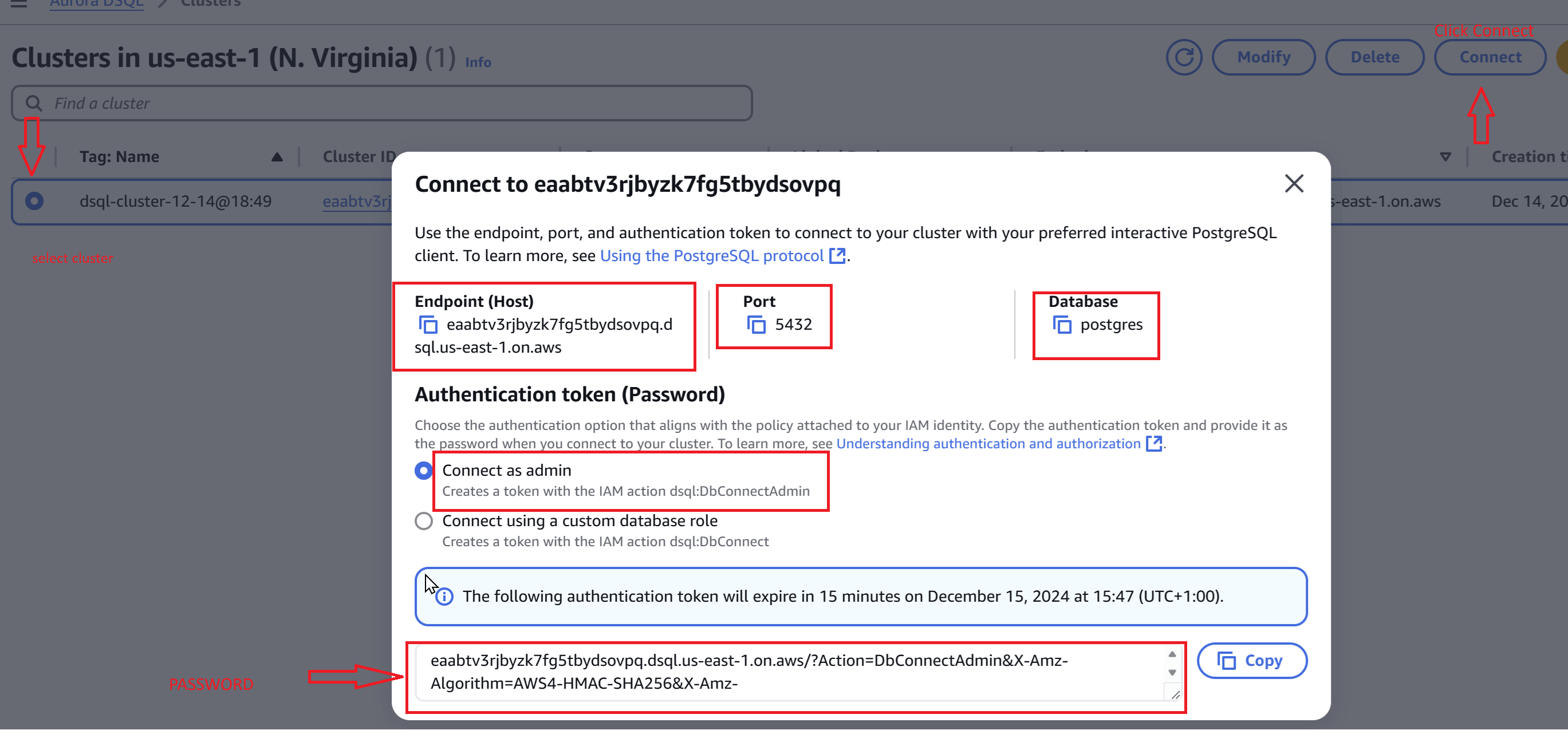
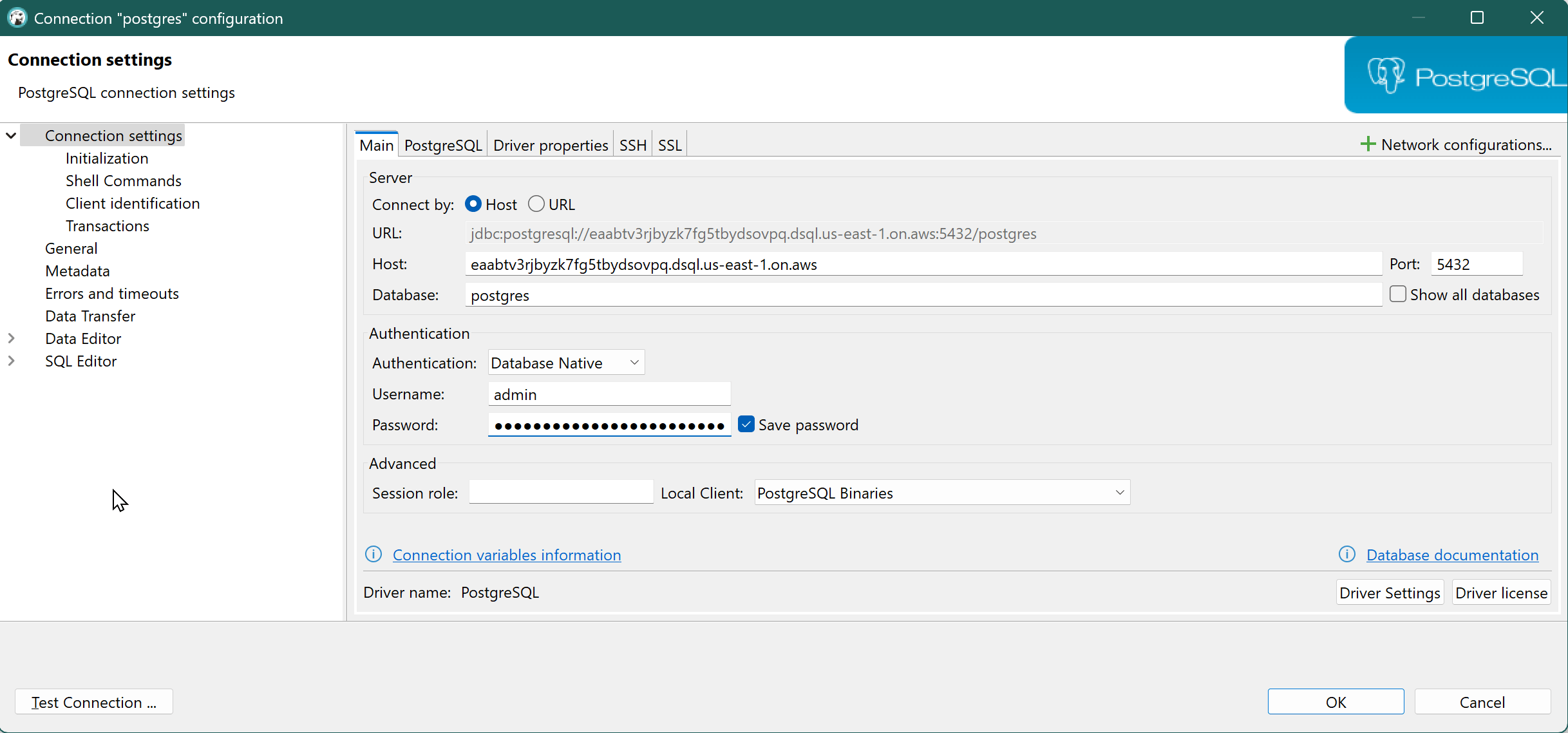
All these connection details are filled in DBeaver, password is valid only for 15minutes, from CLI you can generate longer duration passwords.
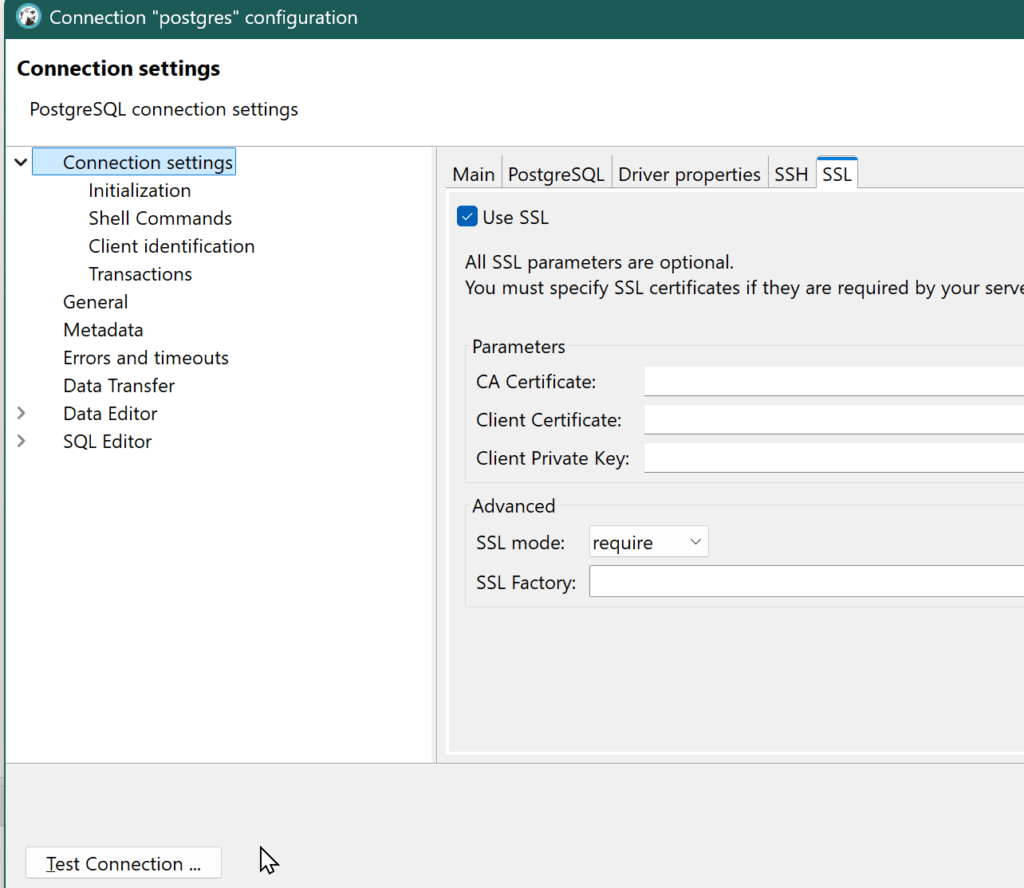
Select SSL Mode require and enable “Use SSL”
I have created a basic product table and did some testing
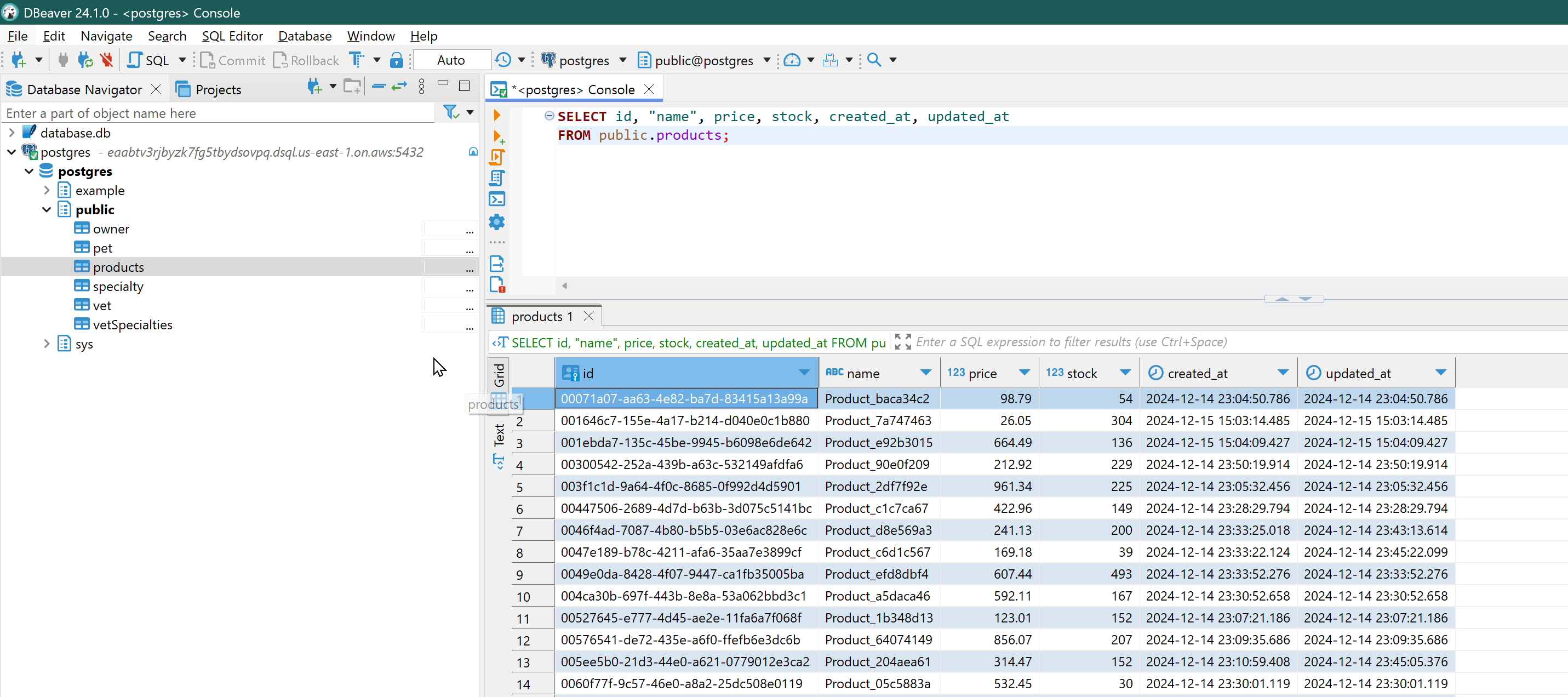
Here is the sample boto3 code for connecting and creating table;
# Product Model
class Product(Base):
__tablename__ = 'products'
id = Column(UUID, primary_key=True, default=text('gen_random_uuid()'))
name = Column(String, nullable=False)
price = Column(Float, nullable=False)
stock = Column(Integer, nullable=False)
created_at = Column(DateTime, server_default=func.now())
updated_at = Column(DateTime, server_default=func.now(), onupdate=func.now())
__table_args__ = (
Index('ix_product_name', 'name'),
Index('ix_product_price', 'price'),
)
def main():
#boto3 session setup , Replace with your own profile name
session = boto3.Session(profile_name='gordion')
# Create a client for the Aurora DSQL, Replace with your own hostname and region
hostname = "eaabtv3rjbyzk7fg5tbydsovpq.dsql.us-east-1.on.aws"
region = "us-east-1"
client = session.client("dsql", region_name=region)
# The token expiration time is optional, and the default value 900 seconds
# Use `generate_db_connect_auth_token` instead if you are not connecting as `admin` user
password_token = client.generate_db_connect_admin_auth_token(hostname, region, ExpiresIn=86400)
DB_URL = URL.create("postgresql", username="admin", password=password_token,
host=hostname, database="postgres")
engine = create_engine(DB_URL, pool_size=10, max_overflow=0, connect_args={"sslmode": "require"})
# Create tables outside of a transaction
with engine.connect() as connection:
Base.metadata.create_all(bind=connection)
Session = sessionmaker(bind=engine)
session = Session()
try:
logger.info("Inserting 1 product")
insert_product(session)
logger.info("Selecting 1 product")
select_product(session)
logger.info("Updating 1 product")
update_product(session)
logger.info("Deleting 1 product")
delete_product(session)
except Exception as e:
session.rollback()
logger.error(f"Error during load testing: {e}")
finally:
session.close()
if __name__ == "__main__":
main()You can find the whole python code here in this GitHub https://github.com/CloudInnovationHub/aurora-dsql-testing
And here are my execution times with that Python code, I tried, single or multi connection, thread as well, but it was pretty consistent. There is still lots of room for improvement but stretching the surface now.
| SQL Operation | Duration E2E |
|---|---|
| Insert | 0.43 – 0.54 seconds |
| Select | 0.33 – 0.54 seconds |
| Update | 0.70 – 0.75 seconds |
| Delete | 0.70 seconds |
Conclusion
In summary, Amazon Aurora DSQL represents a significant advancement in distributed SQL databases, offering a combination of scalability, availability, and ease of management, making it a compelling choice for developers building always-available applications.
Let us know if you like the service or not, where do you want to evaluate.